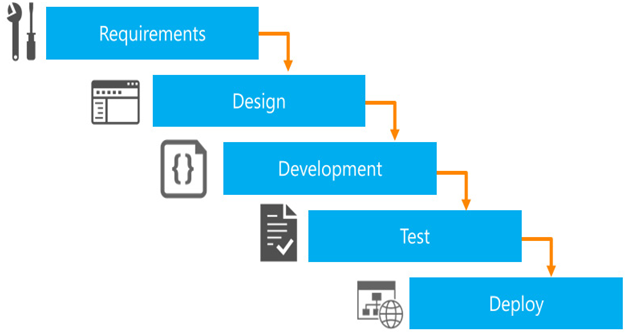
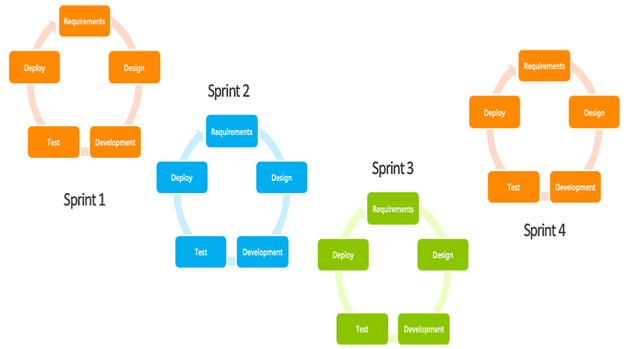
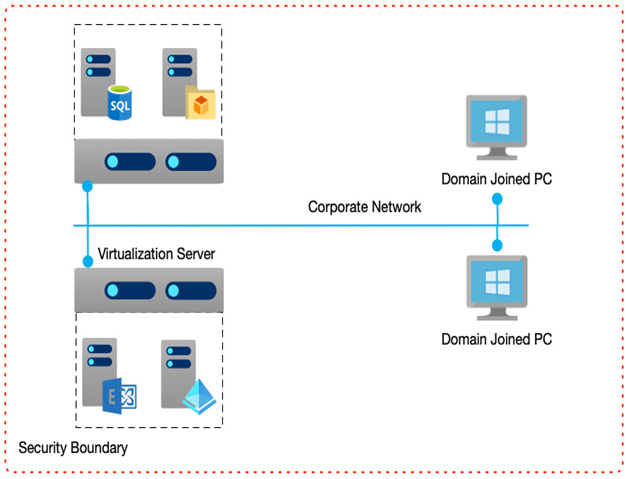
Through years of research and experience, vendors such as Microsoft have collected a set of best practices that provide a solid framework for good architecture when followed.
With the business requirements in mind, we can perform a Failure Model Analysis (FMA). An FMA is a process for identifying common types of failures and where they might appear in our application.
From the FMA, we can then start to create a redundancy and scalability plan; designing with scalability in mind helps build a resilient solution and a performant one, as technologies that allow us to scale also protect us from failure.
A load balancer is a powerful tool for achieving scale and resilience. This allows us to build multiple service copies and then distribute the load between them, with unhealthy nodes being automatically removed.
Consider the cost implications of any choices. As mentioned previously, we need to balance the cost of downtime versus the cost of providing protection. This, in turn, may impact decisions between the use of Infrastructure-as-a-Service (IaaS) components such as VMs or Platform-as-a-Service (PaaS) technologies such as web apps, functions, and containers. Using VMs in our solution means we must build out load balancing farms manually, which are challenging to scale, and demand that components such as load balancers be explicitly included. Opting for managed services such as Azure Web Apps or Azure Functions can be cheaper and far more dynamic, with load-balancing and auto-scaling technologies built in.
Data needs to be managed effectively, and there are multiple options for providing resilience and backup. Replication strategies involving geographically dispersed copies provide the best RPO as the data is always consistent, but this comes at a financial cost.
For less critical data or information that does not change often, daily backup tools that are cheaper may suffice, but these require manual intervention in the event of a failure.
A well-defined set of requirements and adherence to best practices will help design a robust solution, but regular testing should also be performed to ensure the correct choices have been made.
Testing and disaster recovery plans
A good architecture defines a blueprint for your solution, but it is only theory until it is built; therefore, solutions need to be tested to validate our design choices.
Work through the identified areas of concern and then forcefully attempt to break them. Document and run through simulations that trigger the danger points we are trying to protect.
Perform failover and failback tests to ensure that the application behaves as it should, and that data loss is within allowable tolerances.
Build test probes and monitoring systems to continually check for possible issues and to alert you to failed components so that these can be further investigated.
Always prepare for the worst—create a disaster recovery plan to detail how you would recover from complete system failure or loss, and then regularly run through that plan to ensure its integrity.
We have seen how a well-architected solution, combined with robust testing and detailed recovery plans, will prepare you for the worst outcomes. Next, we will look at a closely related aspect of design—performance.