Keeping your applications running can be important for different reasons. Depending on your solution’s nature, downtime can range from a loss of productivity to direct financial loss. Building systems that can withstand some form of failure has always been a critical aspect of architecture, and with the cloud, there are more options available to us.
Building resilient solutions comes at a cost; therefore, you need to balance the cost of an outage against the cost of preventing it.
High Availability (HA) is the traditional option and essentially involves doubling up on components so that if one fails, the other automatically takes over. An example might be a database server—building two or more nodes in a cluster with data replication between them protects against one of those servers failing as traffic would be redirected to the secondary replica in the event of a failure, as per the example in the following diagram:
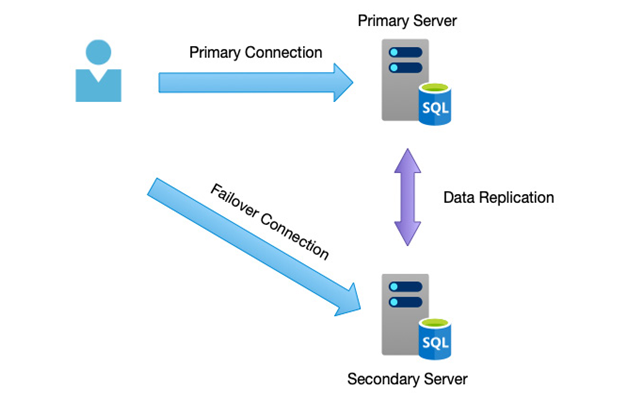
Figure 2.2 – Highly available database servers
However, multiple servers are always powered on, which in turn means increased cost. Quite often, the additional hardware is not used except in the event of a failure.
For some applications, this additional cost is less than the cost of a potential failure, but it may be more cost-effective for less critical systems to have them unavailable for a short time. In such cases, our design must attempt to reduce how long it takes to recover.
The purpose of HA is to reduce the Mean Time Between Failures (MTBF). In contrast, the alternative is to reduce the Mean Time To Recovery (MTTR)—in other words, rather than concentrating on preventing outages, spend resources on reducing the impact and speeding up recovery from an outage. Ultimately, it is the business who must decide which of these is the most important, and therefore the first step is to define their requirements.
Defining requirements
When working with a business to understand their needs for a particular solution, you need to consider many aspects of how this might impact your design.
Identifying individual workloads is the first step—what are the individual tasks that are performed, and where do they happen? How does data flow around your system?
For each of these components, look for what failure would mean to them—would it cause the system as a whole to fail or merely disrupt a non-essential task? The act of calculating costs during a transactional process is critical, whereas sending a confirmation email could withstand a delay or even complete failure in some cases.
Understand the usage patterns. For example, a global e-commerce site will be used 24/7, whereas a tax calculation service would be used most at particular times of the year or at the month-end.
The business will need to advise on two important metrics—the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO). The RTO dictates an acceptable amount of time a system can be offline, whereas the RPO determines the acceptable amount of data loss. For example, a daily backup might mean you lose up to a day’s worth of data; if this is not acceptable, more frequent backups are required.
Non-functional requirements such as these will help define our solution’s design, which we can use to build our architecture with industry best practices.
Leave a Reply