As we have already seen, resilience can be closely linked to performance. If a system is overloaded, it will either impact the user experience or, in the worst case, fail altogether.
Ensuring a performant solution is more than just increasing resources; how our system is built can directly impact the options available and how efficient they are.
Breaking applications down into smaller discrete components not only makes our solution more manageable but also allows us to increase resources just where they are needed. If we wish to scale in a monolithic, single-server environment, our only option is to add more random-access memory (RAM) and CPU to the entire system. As we decompose ourapplications and head toward a microservices pattern whereby individual services are hosted independently, we can apportion additional resources where needed, thus increasing performance efficiently.
When we need to scale components, we have two options: the first is to scale up—add more CPU and RAM; the second option is to scale out—deploy additional instances of our services behind a load balancer, as per the example in the following diagram:
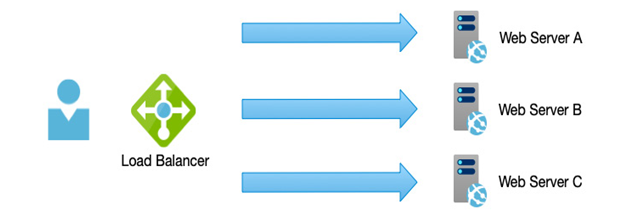
Figure 2.3 – Scale-out: identical web servers behind a load balancer
Again, our choice of the underlying technology is important here—virtual servers can be scaled up or out relatively quickly, and with scale, sets can be dynamic. However, virtual servers are slower to scale since a new machine must be imaged, loaded, and added to the load balancer. With containers and PaaS options such as Azure Web Apps, this is much more lightweight and far easier to set up; containers are exceptionally efficient from a resource usage perspective.
We can also decide what triggers a scaling event; services can be set to scale in response to demand—as more requests come in, we can increase resources as required and remove them again when idle. Alternatively, we may wish to scale to a schedule—this helps control costs but requires us to already know the periods when we need more power.
An important design aspect to understand is that it is generally more efficient to scale out than up; however, to take advantage of such technologies, our applications need to avoid client affinity.
Client affinity is a scenario whereby the service processing a request is tied to the client; that is, it needs to remember state information for that client from one request to another. In a system built from multiple backend hosts, the actual host performing the work may change between requests.
Particular types of functions can often cause bottlenecks—for example, processing large volumes of data for a report, or actions that must contact external systems such as sending emails. Instead of building these tasks as synchronous activities, consider using queuing mechanisms instead. As in the example in the following diagram, requests by the User are placed in a Job Queue and control is released back to the User. A separate service processes the job that was placed in the Job Queue and updates the User once complete:
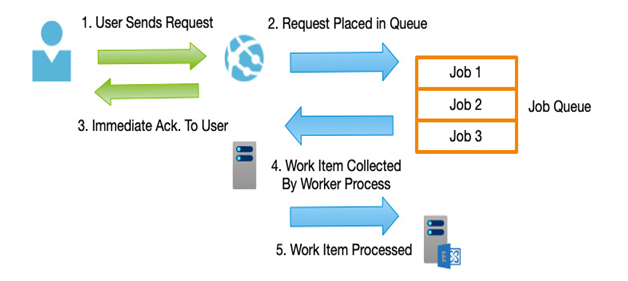
Figure 2.4 – Messaging/queueing architectures
Decoupling services in this fashion gives the perception of a more responsive system and reduces the number of resources to service the request. Scaling patterns can now be based on the number of items in a queue rather than an immediate load, which is more efficient.
By thinking about systems as individual components and how those components respond—either directly or indirectly—your solution can be built to not just scale, but to scale in the most efficient manner, thereby saving costs without sacrificing the user experience.
In this section, we have examined how the right architecture can impact our solution’s ability to scale and perform in response to demand. Next, we will look at how we ensure these design considerations are carried through into the deployment phase.